
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
One in five customers does not have a positive experience with AI chatbots, according to the Qualtrics 2026 Customer Experience Trends Report. Customers feel businesses prioritize cost-cutting over solving issues. However, this doesn't mean AI chatbots are inefficient; rather, it highlights the need for improving the effectiveness of chatbot response generation. This is the point where the Retrieval Augmentation Generation (RAG) architecture becomes significant.
RAG is a design pattern that enhances the performance of LLMs by retrieving data in real-time from external knowledge bases to give smarter, hallucination-free responses. RAG feeds the LLM only relevant and verified company data before generating responses, ensuring accuracy and protecting proprietary info. Thus, chatbots using RAG-LLM architecture no longer need continuous data training and can manage a wide range of queries with content-aware, human-like responses.
Businesses gain the following benefits by using RAG-LLM architecture:
A RAG chatbot provides responses grounded in approved sources, which ensures internal policy compliance and builds customer trust.
While traditional LLMs require retraining and fine-tuning to add or improve data, with a RAG setup, the knowledge scales with the external data.
With RAG, any data can be added or removed without retraining, and the retrieval layer can also filter data based on roles or context.
Generic LLMs are best suited for generating human-like text based on the data it is trained on, such as:
RAG is the suitable choice for performing business tasks in specific situations, such as:
While the outputs from RAG and generic LLMs differ, smart enterprises can use both strategically, LLMs for reasoning and RAG for grounding. With RAG retrieving context and LLM orchestrating complex reasoning, businesses can achieve significant results.
Klarna launched a RAG-based AI assistant to handle customer service worldwide, for tracking orders, managing disputes, and processing refunds. The chatbot reduced average resolution times by 81.8% and improved the annual profit by $40M. The enhanced accuracy of responses led to a 25% decrease in repeat inquiries.
A Fortune 500 manufacturing company built a RAG system to provide instant answers to customer service reps. The fast retrieval enabled quick resolution, and the reps reported 90% five star satisfaction with the system.
A major hospital network integrated RAG into clinical decision support to help businesses make informed diagnoses faster based on the latest medical literature. The integration reduced misdiagnosis by 30% and increased early detection of rare diseases by 40%.
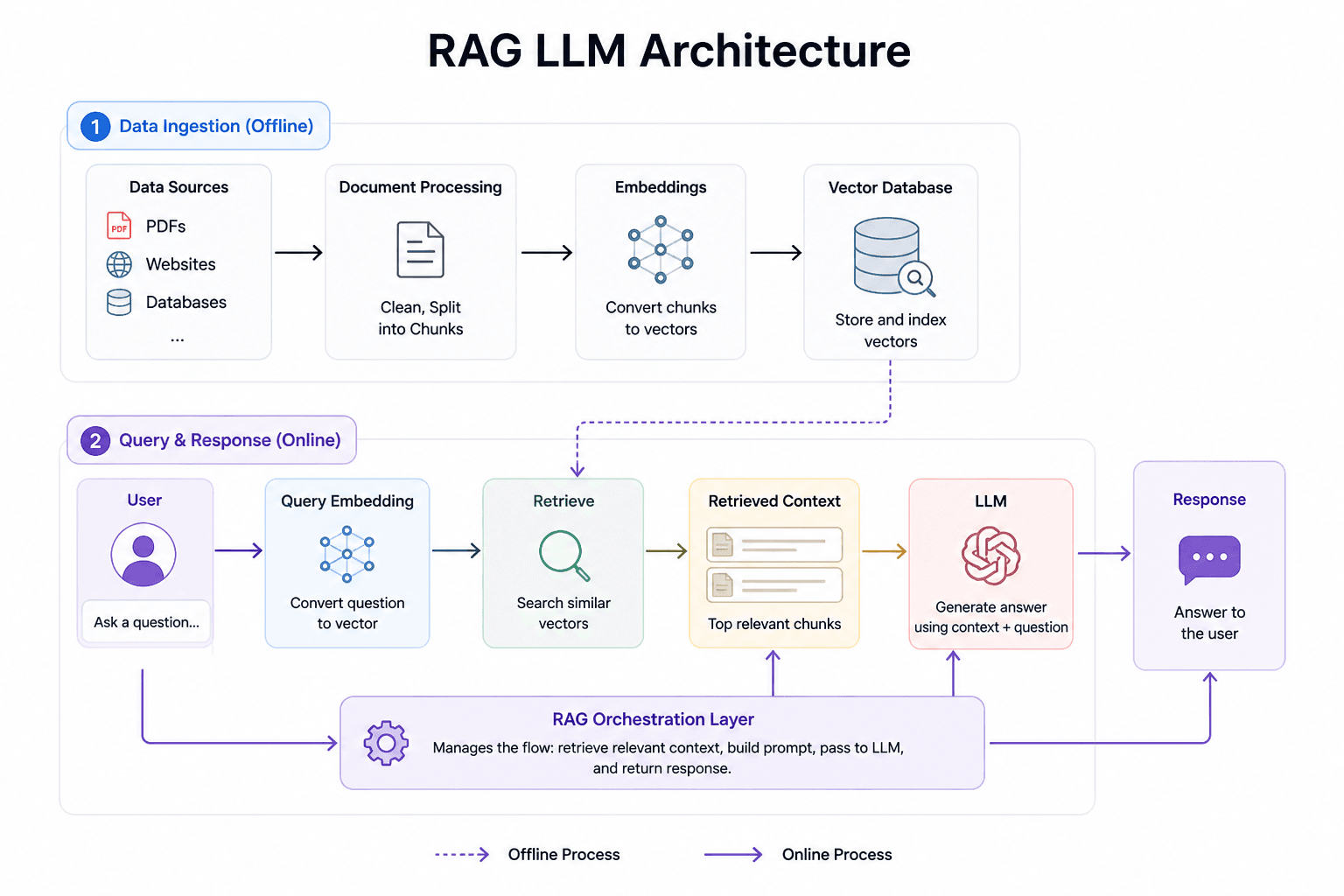
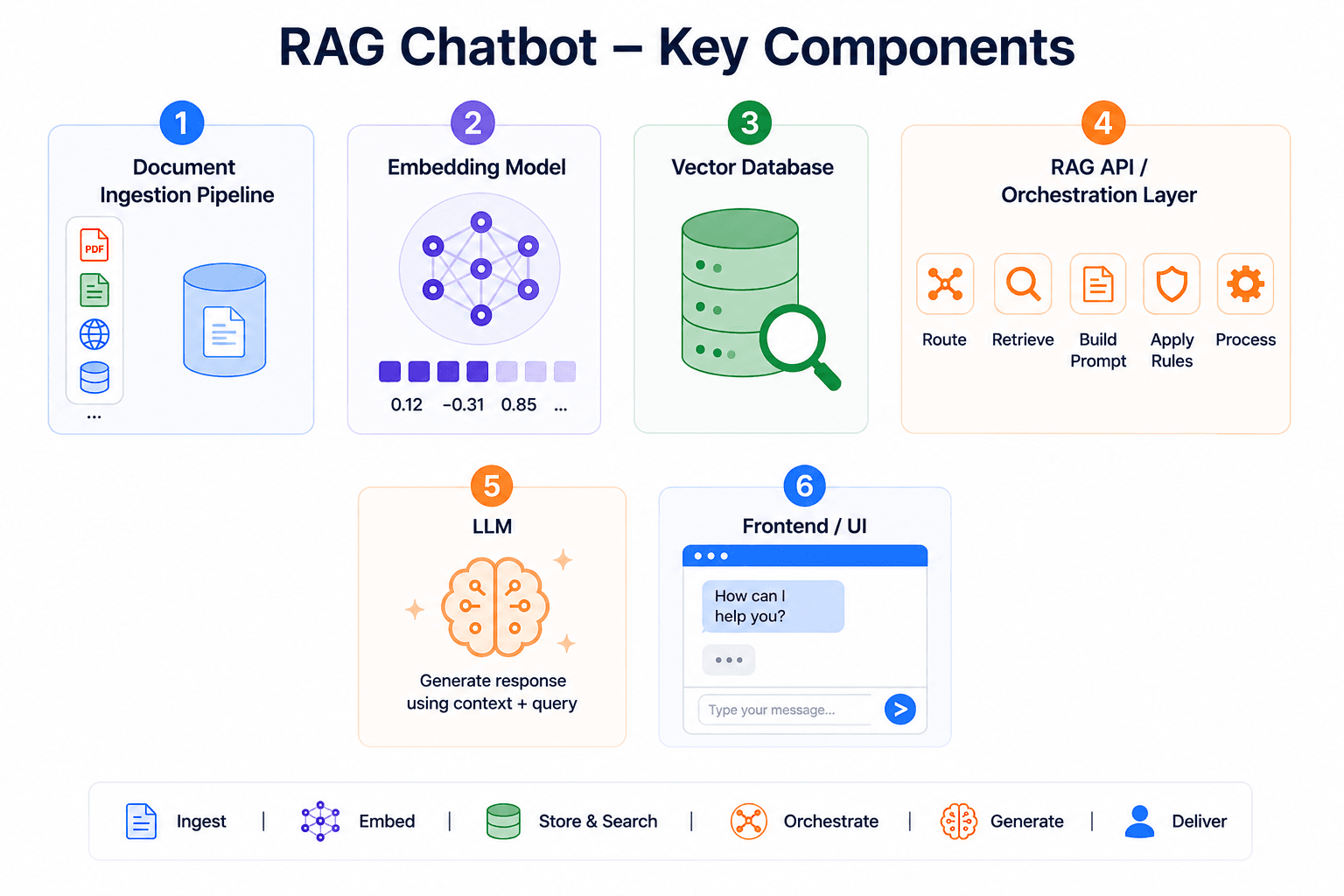
Before you plan to integrate the RAG framework into your existing chatbot or build a RAG-based chatbot, you need to have a basic understanding of the key components and architecture of a RAG chatbot. Here are the essential components of a RAG-based chatbot you should know about:
(Image)
A system that gathers, cleans, and organizes company knowledge from multiple sources and breaks it into usable pieces for the AI.
This model converts customer queries into numerical vectors that the system understands. The system compares the meaning of each query to find similar contexts in the vector database.
A specialized database that stores embeddings (numerical vectors), enabling fast similarity search to retrieve relevant information.
LLM is actually a component of the chatbot that faces the customer. It understands language and generates responses using the query and the retrieved context.
The system that manages everything by sending the customer queries to the database, retrieving information, building prompts, passing it to LLM, while applying rules and controls.
The interface that your customer sees and uses to interact with the chatbot.
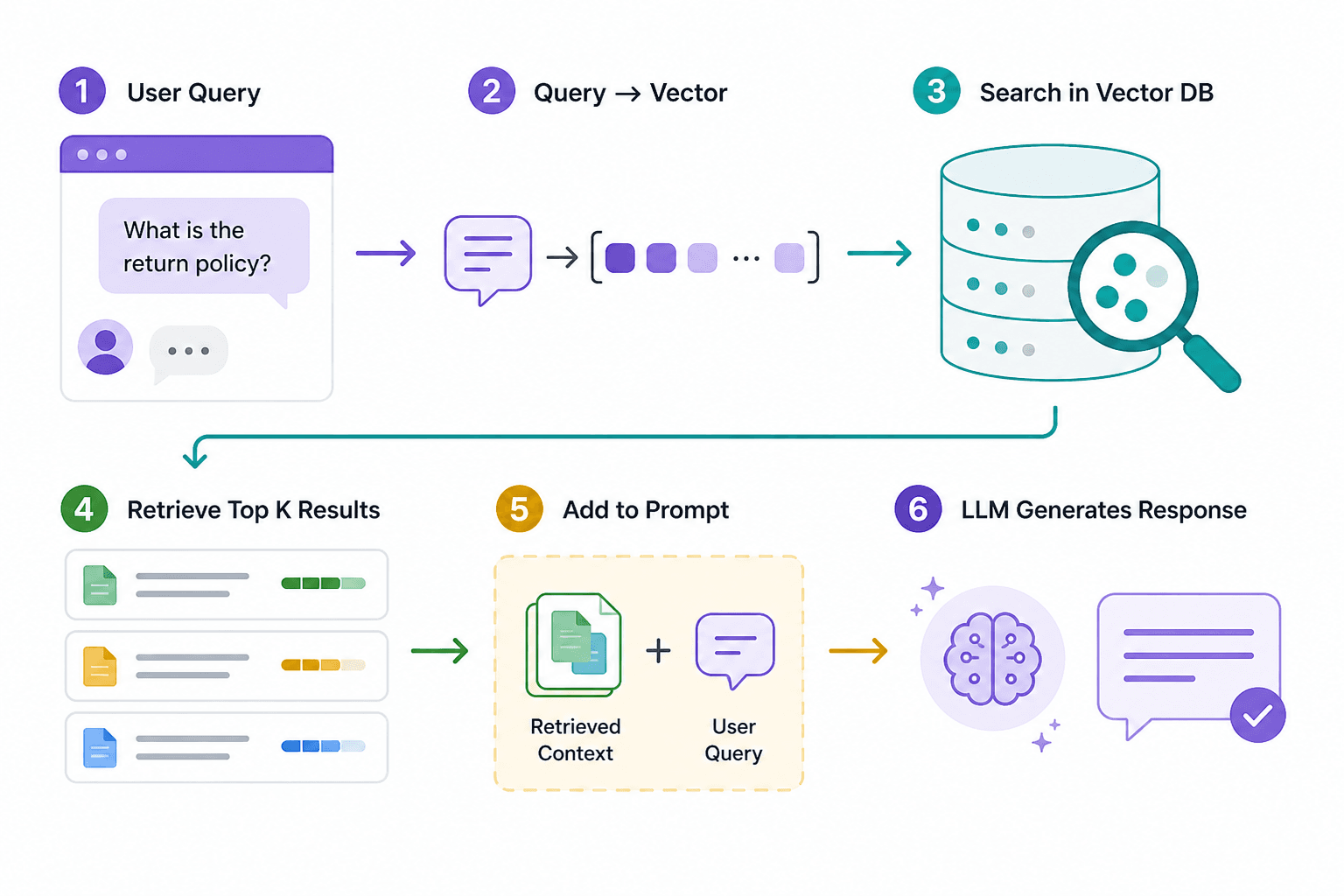
Here is a simple step-by-step process explaining how RAG chatbots generate responses to customer queries.
A simplified view of RAG flow
There are three different ways of implementing an AI chatbot in your customer service, which are:
Build the full system in-house, either by hiring a team of RAG project experts from scratch or an external on-demand team as a faster alternative. This provides full control and ownership over the product and flexibility to optimize the system for your exact use case.
When time is of the utmost importance to you over ownership or flexibility, buy a RAG-based chatbot that turns live for customer use in weeks. You can make it work by connecting your data sources, configuring basic settings, and deploying it. In addition to showing results faster, this option offers higher reliability, lower complexity, and lower risk. SayOne has recently developed the RAG-based product called RealBot 1.0 that companies can buy and deploy by connecting their business knowledge to enhance customer experience.
There is a third choice that offers control and flexibility without compromising reliability and helps you deploy faster than when building. You can start with a base system and customize how it behaves and extend it with your workflows. This way, the chatbot adapts to your business’s evolving needs. At SayOne, we provide the base system of our RAG chatbot in this way, to help businesses deploy faster and have control at the same time. For businesses that do not have an in-house technical team, our developers work as on-demand resources to customize the base model for them, just like their in-house team would.
The chatbots that generate relevant and context-aware responses are also evolving to take actions by combining retrieval and reasoning with action orchestration.
Accurate and relevant actions or responses from chatbots are something beyond technical achievement. They are a strategic factor that differentiates your brand from competitors. When customers get clear and accurate responses at every interaction with your chatbot, they begin to see your business as more reliable and responsive. This translates to something that is the hardest to build: strong trust. Thus, RAG-based chatbots are not just solving your customer queries; they are secretly driving customer loyalty.
Chatbots should never be seen only as cost‑cutting or time‑saving tools; when powered by RAG, they become engines of loyalty and trust, which are far harder to build and more valuable to sustain.
Contact our team to see how RAG can fit into your systems. Our team can guide you through a personalized roadmap for integrating RAG into your existing systems.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality