
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
A recent survey by O’Reilly found that a majority of microservices adopters (up to 92%) had at least some success with its implementation. These indications point to the fact that microservices implementation is beneficial for businesses.
However, implementing microservices for any business comes with a set of challenges. One of the main concerns is managing the database of the microservices system. How should your patterns work when the data is decentralized? How can services remain independent even when the same data has to be accessed by more than one service? Which database model should you choose for your specific application? Many such questions arise. In this blog, we attempt to provide some answers to these questions.
A monolithic application functions with data from a single database. This data is shared between the application’s different components. In contrast, in a microservices application, the data and data ownership is decentralized. Every service is independent and has a private data store according to its functionality. This means that one service cannot modify any data stored inside another service’s database. Most problems start from here.
Whatever the application you build, its microservices will interact and have to share data. If they do not do this, duplication of data will have to take place. In microservices, ACID transactions are not possible for those outside a single service. This condition makes it challenging to implement queries and transactions that require input from several services.
Read our blog, “How to Hire Microservices Developers from Other Countries”.
You have to decompose the database of the monolithic package to derive functionality into the microservices in a way that the data/information is hidden within the microservices. The data of one microservice should be effectively decoupled from that of another. Therefore, during migration into microservices, the monolithic package’s database has to be split properly.
• Determining which parts of the data schema can be safely changed
• Who will control the data
• What is the business logic that will manipulate the data
• Is the data to be used by many services; This may lead to a lack of cohesion in the business logic
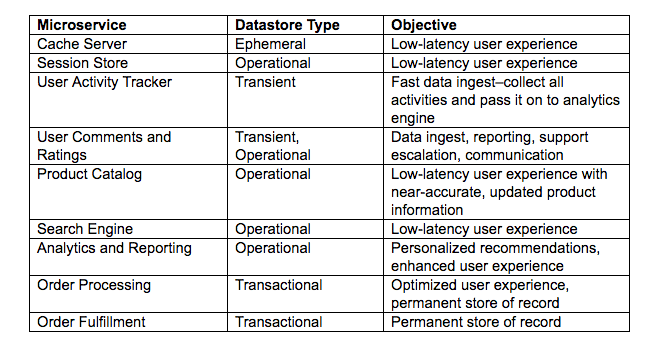
To choose the best data store, you have to first determine the nature of the microservice’s data. The data classification is as follows:
Ephemeral Data
A cache server is an ephemeral data store. This one is a temporary data store and it improves the user experience by serving information in real-time. The microservice that will use this data is typically tuned for read-intensive and high-performance operations.
Download our eBook, "Choose the best microservices vendor and trim the costs."
The cache store has no requirement for durability as it does not store the data master copy. However, it has to be highly available because its failure can cause user experience issues and a fall in revenue. Also, failures can cause “cache stampede” issues, where slower databases become slower because they cannot handle high-frequency access, and this can result in incidents that can be avoided.
Data from logs, messages, and signals are high in volume and velocity. Services that ingest such data typically process this information before sending it to the concerned destination. These data stores are designed to support high-speed writes. Additional capabilities should include the ability to support time-series data and JSON. The durability requirements of transient data are higher than that for ephemeral data. However, this should be the highest for transactional data.
Information from user sessions (user profiles, shopping cart contents, etc.) is grouped under operational data. The microservices using this data offer a better user experience with real-time feedback. The data stored in the database is not a permanent proof of record; however, this data has to be retained for business continuity. For operational data, consistency, data durability, and availability requirements are high. Usually, operational data is organized in a particular model such as a graph, JSON, key-value, relational, etc.
Data gathered from payment and order processing transactions have to be stored as permanent records in a database that supports ACID controls.
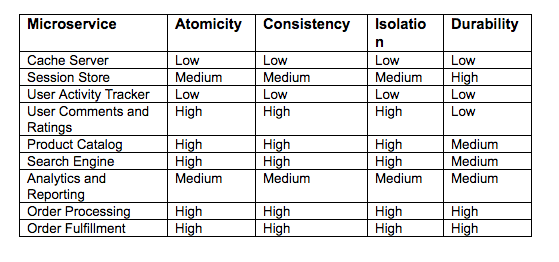
ACID (Atomicity, Consistency, Isolation, Durability) Tuning for microservices
The splitting of the data for microservices is carried out to determine the data ownership. Once this is done, what remains to be done is to implement the structure and method of data management in the corresponding services. The first and foremost job is to figure out the ownership of each bit of data, every field, and their corresponding service. Data decoupling mainly involves the management of data-sharing needs among the different microservices.
Do you want to deploy, manage, and scale up your mobile/on-premise/cloud microservices applications? Call us today!
To share data without any system performance compromise, you can use the CQRS model. This model separates query operations without copying the entire data. Only the partial data required by another business function is extracted and cached. This data has now changed ownership and is not part of the original service. This can be then processed for the generation of newer data.
The best data store for microservices is chosen according to performance, reliability, and data modeling requirements.
For the best performance, every service should provide the best throughput. The read performance (how fast the queries are given and how fast the results are retrieved) write performance (the number of write operations performed per second by the microservice), low latency(delivering instantaneous user response), agility, and resource efficiency of the microservice with minimum database footprint, and provisioning efficiency is some of the parameters that matter.
As far as data modeling requirements are concerned, in microservices, each service can choose a database that suits its data model. The data model employed may be based on the key value, hierarchy, graph, JSON, search engines, and streams, among other factors.
The most important requirement for choosing the microservices database implementation is a flexible deployment model.
• In your data center (either on-premises [VMs/ bare metal] or on the cloud)
• Orchestrated by Kubernetes or other container orchestrators in a containerized environment
• In a cloud-native/PaaS environment (PCF/OpenShift)
Other requirements include:
• High performance, low latency
• High availability, automatic failure detection
• Durability options such as flexible durability
• Orchestration options
You have to take care of microservices data management if you want a high-performance system in place. Choosing data-related patterns and leveraging different approaches to creating data stores and models are vital. However, it is most important to pick a microservices database that will match the requirements of each of your service’s needs the best.
We believe in long-term win-win relationships with our strategic partners. If you want to migrate to microservices, call us today!
At SayOne, we offer independent and stable services that have separate development aspects as well as maintenance advantages. We build microservices especially suited for individuals' businesses in different industry verticals. In the longer term, this would allow your organization/business to enjoy a sizeable increase in both growth and efficiency. We create microservices as APIs with security and the application built in. We provide SDKs that allow for the automatic creation of microservices.
Our comprehensive services in microservices development for start-ups, SMBs, and enterprises start with extensive microservices feasibility analysis to provide our clients with the best services. We use powerful frameworks for our custom-built microservices for different organizations. Our APIs are designed to enable fast iteration, easy deployment, and significantly less time to market. In short, our microservices are dexterous and resilient and deliver the security and reliability required for the different functions.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality