
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
In a microservices-based application, the back-end environment changes in a dynamic fashion. For the clients to be able to keep pace with these changes, they have to be able to identify the service instances that are available to them. Service discovery becomes useful at this instant.
However, the biggest advantage of microservices is that new instances of each service can be created to meet the instantaneous load or respond to failures or roll out new versions/upgrades. The best part is that, unlike a monolithic system, in a microservices system, you can scale different services at different rates according to requirements. Thus, you need not replicate the entire application when a new instance is required.
This capability of scaling individual services according to demand is facilitated with containerization and virtualization technologies that make for quick replication of multiple instances of service without actually bothering about the hardware infrastructure that supports the service.
Read our blog “Do microservices require API Gateways?”
However, an accompanying side effect of such an action is that the service instances’ addresses (IP address and port) keep changing hourly or even within minutes. Therefore, to route a request to a specific service, the API gateway has to determine the address of the service instance that is required. Unlike in the past, a configuration file is not sufficient. The requirement is for a dynamic environment in which the instance addresses are added or removed as they change, and for this, an automated solution is a must.
When multiple instances of a service are working, one also has to answer the question of how traffic is distributed across these instances. A traditional load balancer may not be able to keep up in such a dynamic environment. This is where service discovery can step in and help. It provides a mechanism using which the system can keep track of available instances and then distribute requests across these available instance
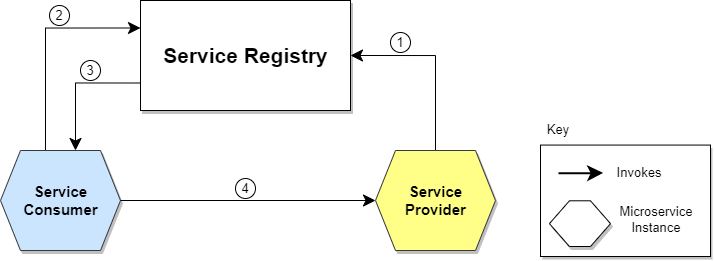
A microservices registry is what maintains a list of the available service instances in an application. This registry has to be updated every time a service is newly available. Similarly, for those services that are unavailable, the registry has to be accordingly modified. This is achieved using self-registration or by using third-party registration methods.
A circuit breaker in microservices architecture plays a crucial role in managing service failures and maintaining the stability of the system. It acts as a safety mechanism that prevents a failure in one service from cascading to others. The circuit breaker monitors the health of service calls and "trips" when a threshold of failures is reached, effectively preventing further requests to the failing service.
In the context of a microservices registry, when a service goes down or becomes unhealthy, the circuit breaker mechanism comes into play. It helps ensure that the registry doesn’t continuously attempt to route traffic to a service that’s unavailable. Once the circuit breaker is tripped, it triggers a fallback process and the service is removed or marked as "unavailable" in the registry. The registry, in this case, reflects the current state of service availability, which is crucial for ensuring the resilience and reliability of the system.
Microservices communication is crucial for enabling seamless interaction between various service instances. Once a microservices registry is established and continuously updated, it facilitates efficient communication by allowing services to discover and connect with each other dynamically. Services can use lightweight protocols like HTTP/REST or more complex ones like gRPC for synchronous communication, while message brokers can handle asynchronous communication through messaging queues.
Here, each microservice is made responsible to add its address to the service registry as it becomes available online. For this, a service registry exposes a REST API using which the service can register itself with a POST request or remove itself using a DELETE request.
Download our eBook for free “MICROSERVICES- A Short Guidebook”.
To make this fail-poof, instances send heart-beats to the service registry in order to indicate that they are still available online. The stoppage of any heart-beat is an indication that the service instance is offline. In such a case, this service can be removed.
Self-registration can be designed using simple methods. However, you have to implement the logic for registration in every language/framework that is used in the microservices.
For high-performance microservices that are resilient as well as scalable, call us at SayOne today!
Third-party registration solutions are often more loosely coupled. A service registrar/manager is responsible for the registration of every new instance when it comes online. It is also responsible for deregistering services as they become unavailable.
The service registrar accomplishes this action by subscribing to event notifications or polling the deployment environment for updates. Though it gives the feeling of a lot of overhead, deployment environments like Kubernetes/Amazon EC2 have built-in service registries and third-party service registrars. These can save you the additional work of implementing and maintaining service registries which also have to be highly available components.
To send any API request to a specific service, the client/API gateway should know the location of the service that it is addressing. The microservice architecture is designed to support many instances of each service. Therefore, service discovery is closely linked to load balancing of the requests to instances of each microservice. It is vital to note that load-balancing requests across service instances are totally separated from load-balancing incoming client traffic across different API gateway nodes.
In the client-side discovery model, the client/API gateway which makes the request has to identify the service instance location and then route the request to it. The client starts this process by querying the service registry in order to identify the locations of the service’s available instances and then decide which instance to use. The load balancing logic is usually a round-robin approach or a weighted system to pick out the best instance to which the request can be passed.
Client-side discovery can also be achieved using a ring balancer. The service registry keeps a record of the available target instances for upstream services. When a target becomes available, it must register itself by sending a request to the Admin API. Here, every upstream service has its own ring balancer that will distribute requests to available targets. Here, the ring balancer uses a weighted round-robin scheme, but can also be configured by using a hash-based algorithm.
Both active and passive health checks can be run on the targets to find out if they are healthy or not. Whereas periodic requests to each target are sent during active health checks, during passive health checks there is no additional traffic generated. They monitor requests that are proxied to each target, and any that fail to respond are marked as unhealthy. The ring balancer distributes requests only to healthy targets.
Read our blog on “Introduction to Ecommerce Microservices Architecture”.
The server-side discovery decouples the load-balancing logic and service discovery from the client. Here, the client/API gateway passes on the request directly, including the DNS name, to a router. The router in turn queries the service registry (which may be built-in to the router or a separate component) to identify the available instances of the service. The load-balancing logic is then applied to decide which one has to be used.
Some deployment environments include this functionality as part of their service offer. This will save you the effort of setting up and maintaining additional components related to this. In such a case, the client/API gateway needs to just know the router’s location.
Conclusion
Dynamically determining the location of a service is not an easy matter. Things get more complicated when the environment is one where some service instances are constantly destroyed and other new service instances come into play.
Are you looking to deploy, manage, and scale up your Kubernetes microservices applications in the cloud? Call us today!
At SayOne, we offer independent and stable services that have separate development aspects as well as maintenance advantages. We build microservices especially suited for individuals' businesses in different industry verticals. In the longer term, this would allow your organization/business to enjoy a sizeable increase in both growth and efficiency. We create microservices as APIs with security and the application built in. We provide SDKs that allow for the automatic creation of microservices.
Our comprehensive services in microservices development for start-ups, SMBs, and enterprises start with extensive microservices feasibility analysis to provide our clients with the best services. We use powerful frameworks for our custom-built microservices for different organizations. Our APIs are designed to enable fast iteration, easy deployment, and significantly less time to market. In short, our microservices are dexterous and resilient and deliver the security and reliability required for the different functions.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality