
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
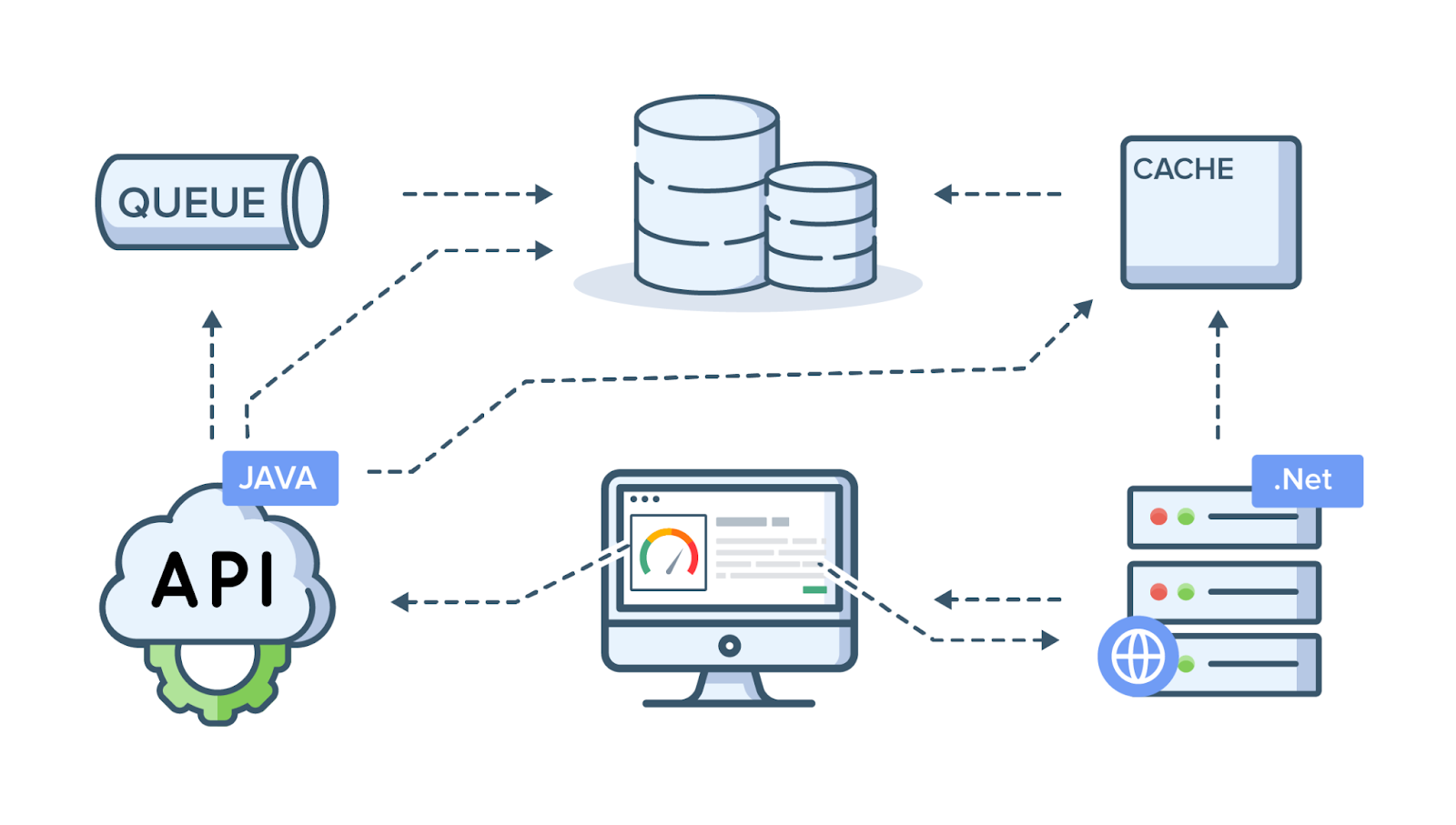
Microservices architecture has introduced perhaps the best way to scale an application (in the cloud) using several independent services. This architecture model facilitates scalability, high resiliency, productivity, and efficiency when compared to the monolithic architecture software model. However, this brings on additional complexities including difficulty in tracing out bugs or monitoring traffic flow across the entire system.
Distributed tracing was introduced to eliminate these complexities. This method helps in solving high-level debugging issues and also improves visibility within the network. It supports developers by narrowing down the errors and end-to-end latency that a specific service/ function experiences at any moment.
Observability is all about monitoring the behavior of the infrastructure at granular levels. This affords maximum visibility within the infrastructure and supports the crisis management team to improve and maintain the reliability of the architecture.
Read our blog “Microservices Monitoring and Tracing tools”.
Observability is accomplished by recording the system data in different forms such as metrics, alerts or events, logs, and traces. These functions help to derive insights into the system’s internal health.
Tracing refers to the continuous supervision of the flow of an application and its data progression that is represented by the journey of a single user through an app stack. This helps to make the behavior of the app more obvious and understandable. Distributed request tracing is an evolved method of observability that will help to keep cloud applications in good health.
Distributed tracing refers to the process of tracking a transaction request and recording all the connected data throughout the path of the microservices system. This method is now being used across enterprises to inspect and visualize microservices systems in a well-structured manner. This method of data tracing helps SRE/DevOps teams to understand and quickly scrutinize the technical issues that cause abnormalities within the system infrastructure.
Download our eBook for Free “MICROSERVICES- A Short Guidebook”.
Tracing can be done by using tools such as OpenTelemetry, a standardized framework to enable observability in cloud-native applications, which provides a vendor-neutral approach to tracing.
Recent trends have pointed to the fact that a majority of traditional enterprises are changing their software architecture model into microservices. This shift from monolithic to microservices architecture has necessitated data tracing in heavily distributed systems to avoid the challenges of encountering frequent technical issues. Distributed tracing helps to monitor microservices systems at granular levels.
As an example, an interactive social gaming platform will have millions of users across the globe belonging to all age groups. If a specific user has checked in some preferences on the platform, the system has to process this data with tight latency and deliver the appropriate outcomes to the user. Here, distributed tracing helps to capture each user’s requests, process them across various microservices, and deliver the expected result within a fraction of a second.
Read our blog : Is Microservices Architecture Beneficial to Business Agility
In the following passages, we can observe how distributed tracing will help the gaming infrastructure handle different issues.
Providing end-to-end (E2E) visibility across the infrastructure
In the gaming platform example, distributed tracing would help to track the user's location, and demographics, and store the details within the system. It follows a user request and records all the associated data. Using this functionality, the platform would be able to achieve E2E visibility inside its architecture.
Providing information about service dependencies
Every service in a microservices environment is interdependent on other services while accomplishing any user request. In the gaming platform example, every player is intimated of any status change that is updated by a single player. For this, the central server and various other locality-based nodes have to be accessed within the architecture to accomplish this task. Therefore, each service request will have to receive and give information about various other dependent services along the user request execution path.
Ensuring resiliency when the system encounters a failure
Consider the situation when an in-app purchase module in the gaming platform encounters a failure because of invalid user credentials. If distributed tracing is used, the developers can easily identify the API flow trace (of the payment portal) and rectify the failure instead of searching through different information logs. When every transaction along with necessary network data is recorded, it helps to save a large amount of time.
Do you want to migrate to microservices? Talk to us today!
Given below are a few basic terminologies associated with distributed tracing.
A single trace contains a series of spans having associated tags.
The following paragraphs explain how distributed tracing handles a single user request.
Distributed tracing starts right away when the end-user begins interacting with a system or application. For example, when a new user signs up for an interactive mobile gaming platform, the user will have to enter an email id and a password.
Each user request is converted into an HTTP request and is then assigned a unique trace ID (Global ID). The user data would be fetched and assigned using this unique ID.
Read our blog : How Can Microservices Help Omnichannel Retailers
When the request travels through the host system, every operation of the system is counted in terms of a span, and associated sub-operations are counted as child spans. The first span of a trace is also referred to as the root span. In the gaming platform example, the email id is the root span and the password would be a child span.
Every user operation is tagged with three IDs, namely: request trace ID, parent span ID, and child span ID. Here, every span is denoted with three IDs. Every unique user request (Span) is recorded with all the related information (tags) required for processing the request. This data includes the following:
All these processed data get attached to a Global ID that contains relevant information about the path that a trace is following from its source to a destination. Also, all the information about the trace in the user request’s journey is finally stored inside the corresponding data storage facility. In this case of the gaming platform example, the data would be stored in the backend server's database tier for any future reference.
There are separate tools that are used for performing distributed tracing across the architecture and these are placed under three categories.
Code Tracing Tools: these help to perform tracing during the execution of a code unit. These tools help to trace every line of code, the variables, conditional statements used, and iterative functions and finally deliver the expected output. These help in code analysis and diagnosis of errors. Some code tracing tools are OpenZipkin, OpenTracing, and Appdash.
Data Tracing Tools: these tools help to execute tracing during validation of the critical data elements (CDE)/telemetry data with the source system and monitor them using statistical process control (SPC) methods. Examples of data tracing tools are Jaeger, Datadog, New Relic, Lightstep, and Dynatrace.
Read our blog :Benefits of Moving Enterprise Retail to Microservices Architecture
Program(Process) Tracing (ptrace) Tools: These establish tracing operations during the application execution. These tools maintain an index of the instructions executed and the data referenced during execution. These are frequently used by developers for purposes of debugging. Some examples of ptrace tools are Ltrace, Strace, Valgrind Lackey, and Opensnoop.
We are providing a few links that can help you in getting started with distributed tracing in your microservices architecture system.
To track system requests along the network path and to understand why microservices systems don’t work as expected, check .
You can follow the steps outlined in the following link to implement distributed tracing across your architecture: OpenTelemetry (OpenTracing + OpenCensus)
If yours is an organization that has Jaeger running natively across Docker you can follow the steps in the Jaeger documentation.
In case you have configured your infrastructure with Java/Docker, you can follow these steps to apply OpenZipkin across your infrastructure.
To apply a distributed tracing pattern for your architecture refer to the following: Distributed tracing pattern.
In case you want to implement distributed tracing across your microservices-based web application, refer to the IBM Garage methodology.
To understand microservices architecture and its behavior when using distributed tracing, check out Understanding Microservices with distributed tracing.
Executing or practicing the above strategies can help you implement a distributed tracing system across the microservices architecture system in your organization.
However, Now, with the increased adoption of distributed tracing, there are practical challenges that come along. In order to stay reliable, it is vital to maintain best practices while implementing this functionality.
Best practices to be followed when adopting distributed tracing in a microservices architecture:
Conclusion
Distributed tracing is, therefore, an efficient technique for monitoring microservices architecture. It provides precise data and information about the network path. Adopting standardized distributed tracing tools together with E2E instrumentation of SRE golden signals metrics, allows you to overcome the challenges while implementing distributed tracing in a microservices software system.
Looking for the best microservices vendor? Give us a call today.
At SayOne, our integrated teams of developers service our clients with microservices that are fully aligned to the future of the business or organization. The microservices we design and implement are formulated around the propositions of Agile and DevOps methodologies. Our system model focuses on individual components that are resilient, fortified, and highly reliable.
We design microservices for our clients in a manner that assures future success in terms of scalability and adaptation to the latest technologies. They are also constructed to accept fresh components easily and smoothly, allowing for effective function upgrades in a cost-effective manner.
Our microservices are constructed with reusable components that offer increased flexibility and offer superior productivity for the organization/business. We work with start-ups, SMBs, and enterprises and help them to visualise the entire microservices journey and also allow for the effective coexistence of legacy systems of the organization.
Our microservices are developed for agility, efficient performance and maintenance, enhanced performance, scalability, and security.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality