
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.

Generating table of contents...
Tracing a distributed system provides many valuable insights into how our application is functioning. With computing architecture having taken a tilt towards microservices taking over traditional monolithic systems, distributed tracing has become a very vital component in determining the functional health of the system. In the year 2021, 85% of respondents in a survey who were from large organizations (5,000 or more employees) stated that they were currently using microservices.
Monitoring and distributed tracing help to improve the observability of your production system better the action of the feedback loop so that your development process becomes more efficient and effective.
‘Monitoring’ the health of your production system means keeping track of different data points, in real-time, so that you can derive actionable insights from them. Everyday monitoring can help you to detect potential problems early enough, thus giving the team enough time to investigate and fix the issues before the system comes to a standstill. In case you running production-stage tests, such as canary releases/blue-green deployments, a monitoring tool will best measure the impact of the release. This can help you to decide whether to roll out or roll back.
In case your services are hosted by a third-party cloud provider, it seems that you do not have to monitor system metrics such as I/O, disk space, CPU and memory usage. However, if you do monitor these parameters, they provide a good indication of the health of your services and if you observe them soon after changes have been released, the parameter values can tell you a lot about the performance of your code.
Download our eBook for Free “MICROSERVICES- A Short Guidebook”.
Measuring the time taken for a client request to be processed, including that taken by the individual services involved in the request, provides you with a performance baseline. An increased latency degrades user experience and can also indicate the presence of an underlying issue.
Monitoring the different types of errors being generated by the system indicates problems in the behavior of specific services. It can also indicate how clients are interacting with the system. Whereas distributed tracing can be used to track down the problems in the services, the latter may indicate an issue with the public API/its documentation.
Read our blog “Startup-SMB-Enterprise Microservices Architecture Adoption Timing”.
Your observed metrics should also contain business KPIs. Though these may appear irrelevant to your developers in the beginning, any change from normal values can raise a red flag and indicate an underlying issue. If there is a decrease either in the number of purchases, data views, or signups, there may be a problem with performance or functionality that stops users from accessing your system.
Most monitoring solutions come with a dashboard so the stakeholders can see the state of the system. The configurable alerts would notify you when values pass specific thresholds. However, when setting up alerts, it is important to keep in mind the signal-to-noise ratio; if a threshold is set too low, teams would soon ignore them and will likely miss the important ones. With experience, you will get to know the signs that something is likely to go wrong or fail, and you can adjust the threshold accordingly so that you get time to take pre-emptive action.
Read our blog : Why Business leaders should care about Microservices
In microservices systems, incoming traffic is directed via an API gateway which provides access to upstream services. This means the gateway is a good vantage point at which you can integrate a monitoring solution. The gateway may be designed to support plugins that monitor the health of your system. You can have options to store the data yourself or otherwise send it to a hosted service. There could be a system set up to monitor metrics for upstream microservices, such as request counts and status codes.
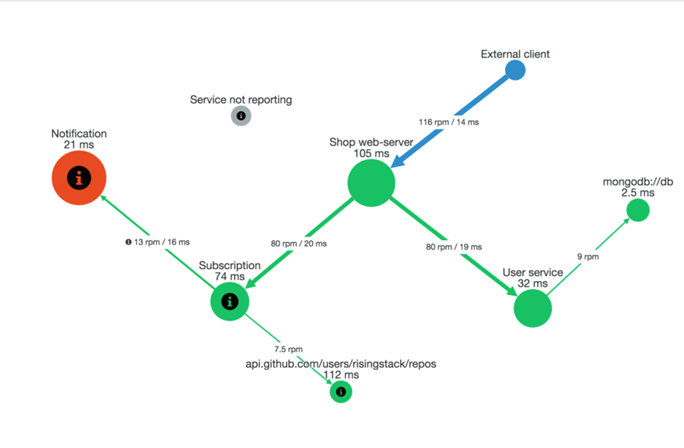
Whereas monitoring enables the collection of metrics and aggregates data over time to show the trends, distributed tracing is designed to focus on a single operation. Although originally developed to measure and improve performance, distributed tracing can be used for debugging in a microservice-based system.
Do you want to migrate to microservices? Talk to us today!
Stack traces can be used for monolithic applications to understand the context of an error. However, with microservices, a single request can give rise to multiple requests for individual services that may be hosted on different machines. If the failure occurs at one point in the system, every interaction between that service and others or other parts of the system is likely to be a possible cause, and simply looking at the individual log files will not be able to give you the full reason or context of the error. Any increase in latency can be because of one or several components. To debug the issue, you have to be able to piece together the entire chain of requests that led to the result. Distributed tracing is what helps to decipher the actual error from the train of events.
With distributed tracing used, a unique identifier is applied to every single request coming into the system and propagated to every request sent to the individual microservices and also to any child requests that are generated. To get a complete trace, this identifier should be included in the response sent to the client. In the case a user reports an error, the identifier in the response received is used for replaying the entire transaction, locating the relevant logs, and identifying the root cause.
Read our blog: Microservices Architecture & the most important design Patterns
It’s best to implement distributed tracing early on when setting up the system, as it requires the instrumentation of all the code in your system. Missing any one of the individual segments in a transaction will create a blind spot in the trace, and this will make it harder to get to the bottom of a problem.
Concluding thoughts
The main advantage of microservices over a monolithic architecture is the ability to deploy new features/changes quickly. If you can identify issues in production quickly and proactively and can debug the cause thereof, you roll out/roll back versions or changes promptly and minimize the financial/reputational damage from the occurrence of failures. The next step would be to add automated tests to prevent a similar issue from occurring in the future. A continuous feedback and improvement system helps to build a robust product without slowing down the development and deployment. This means that teams can continue to innovate and keep up with evolving user needs, ensuring that your product remains valuable to your users.
Looking for the best microservices vendor? Give us a call today.
At Sayone, we design and implement microservices systems that do not have complex architectural layers, and this enables the services to deliver exceptionally fast performance. Moreover, we provide services that are significantly decoupled, allowing you to launch independent services and not end up with the usual inter-dependent microservices that work more or less like a monolith.
We design the microservices keeping in mind the margin required to allow for the transitioning into the new system of your organization’s legacy architecture as well as expanding into the cloud system. Our microservices comprise lightweight code and we provide competitive pricing options for our clients.
Our microservices are built according to the latest international security guidelines that ensure complete safety of all the data. We also ensure that we deliver the services within stipulated deadlines and we always assure a quick turnaround time for our clients. Equipped with the best infrastructure and the latest tools and technologies, our expert developers will provide you with the best microservices that are easily scalable, enabling a good ROI in the shortest period of time.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality