
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
It is an accepted fact that microservices architecture transforms the process, practices, and outcomes of software development in many ways. It is the inability of monolithic architecture in meeting the demands of modern applications that led to the development of microservices. According to an O’Reilly survey, most businesses (about 92 percent of the respondents) that have adopted microservices architecture for their organization have experienced some amount of success. However, one of the challenges posed by this architecture is the maintenance of data consistency across microservices.
In this post, we will discuss in detail as to how we can make microservices database management more effective. Besides, we will discuss aspects such as patterns you should use to solve data decentralization issues, how you can make services store more data without compromising their independence, and the best microservices database model for an application development project.
In the case of a monolithic application, data is shared with different components of the app from a single database. On the other hand, data ownership is decentralized in the case of a microservices app and each autonomous service separately stores data that it needs to perform its function. As a result, one service cannot modify the database of another service.
Read our blog “The Journey into Microservices at SoundCloud”.
Irrespective of the type of application you create, microservices have to interact with each other and share data so as to eliminate consistency issues such as data duplication. As ACID transactions cannot be used in the case of microservices, it is a challenging task to implement transactions and queries that need interaction between different services.
The best strategy you can employ to overcome the challenges with respect to the management of databases is using different types of microservices database patterns that are available. Five of the commonly used patterns are discussed below:
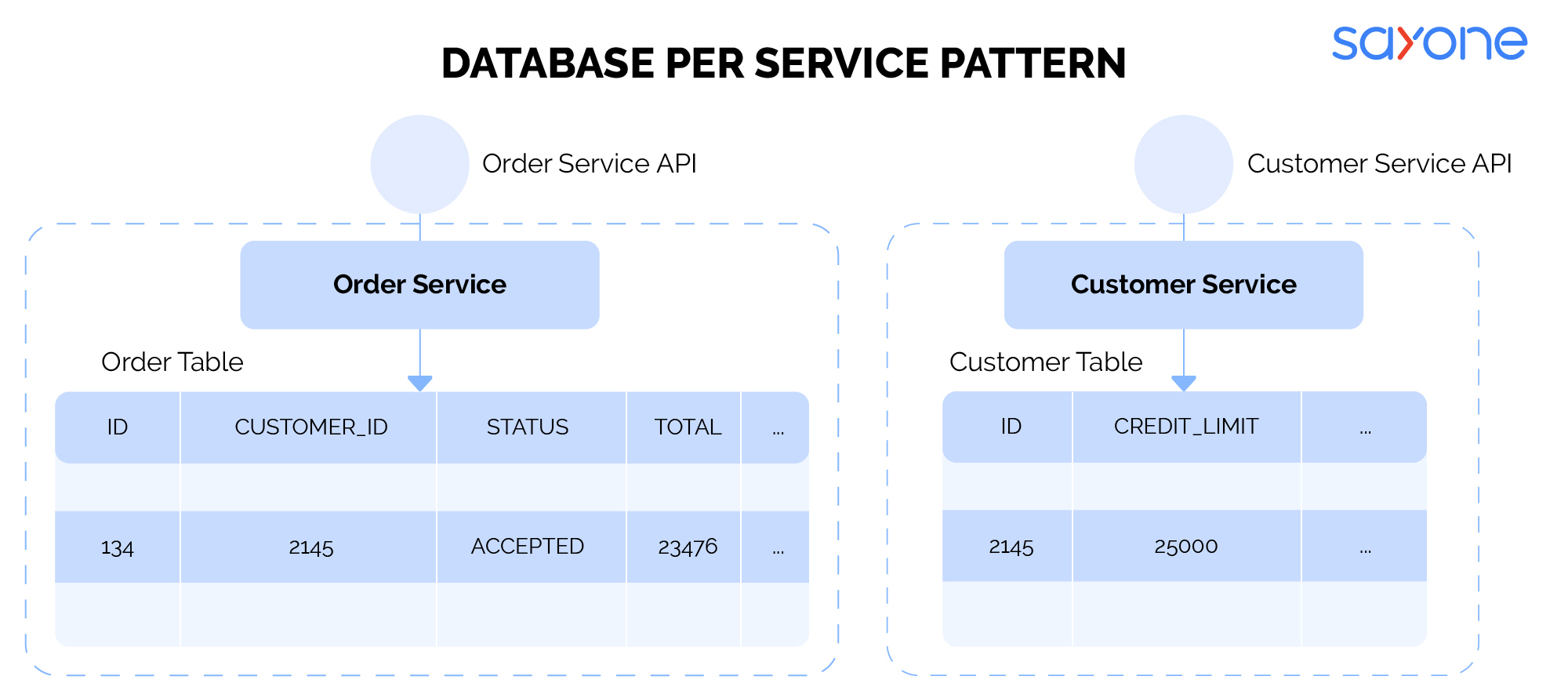
1: Database-per-Service pattern
The Database-per-Service pattern is the best choice when scaling and testing specific microservices as it offers the flexibility to choose a database. Since the databases remain isolated from each other, this pattern makes use of APIs to establish communication or exchange data. However, this pattern may not be suitable for larger and complex applications as there will be many microservices databases to deal with. Further, the successful execution of business logic becomes difficult as an API gateway has to intervene and fetch the data and interact with different databases. As such, the database per-service pattern is the right choice for apps with limited scope.
Take a look at how SoundCloud has implemented microservices architecture.
2: Saga pattern
There are two parts to the Saga pattern. There are:
Choreography-based Saga – Communication happens through the exchange of events.
Orchestration-based Saga – Saga participants are invoked with the help of centralized control and using requests/responses.
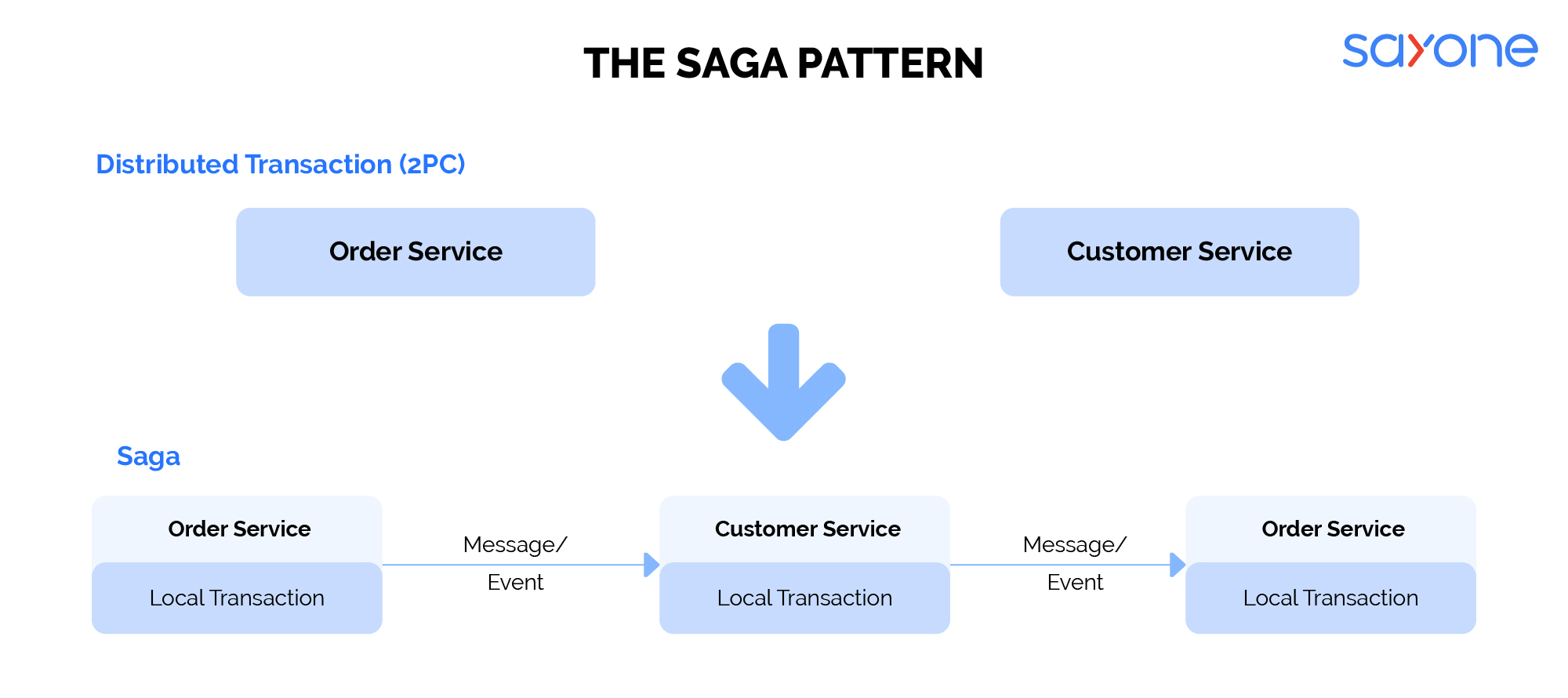
In the case of applications with multiple transactions, the saga pattern is the best microservices database management option. For imagine, imagine that a customer places an eCommerce order. Two services – order service and customer service – will interact with each other. The saga communicates with the eCommerce store via the order service to manage the order placement events. On getting confirmation, the order service sends the reply. The saga approves or rejects orders based on the reply. If approved, the order status is communicated to the customer with the expected delivery date once the payment is completed. If not, an apology message is sent to the customer.
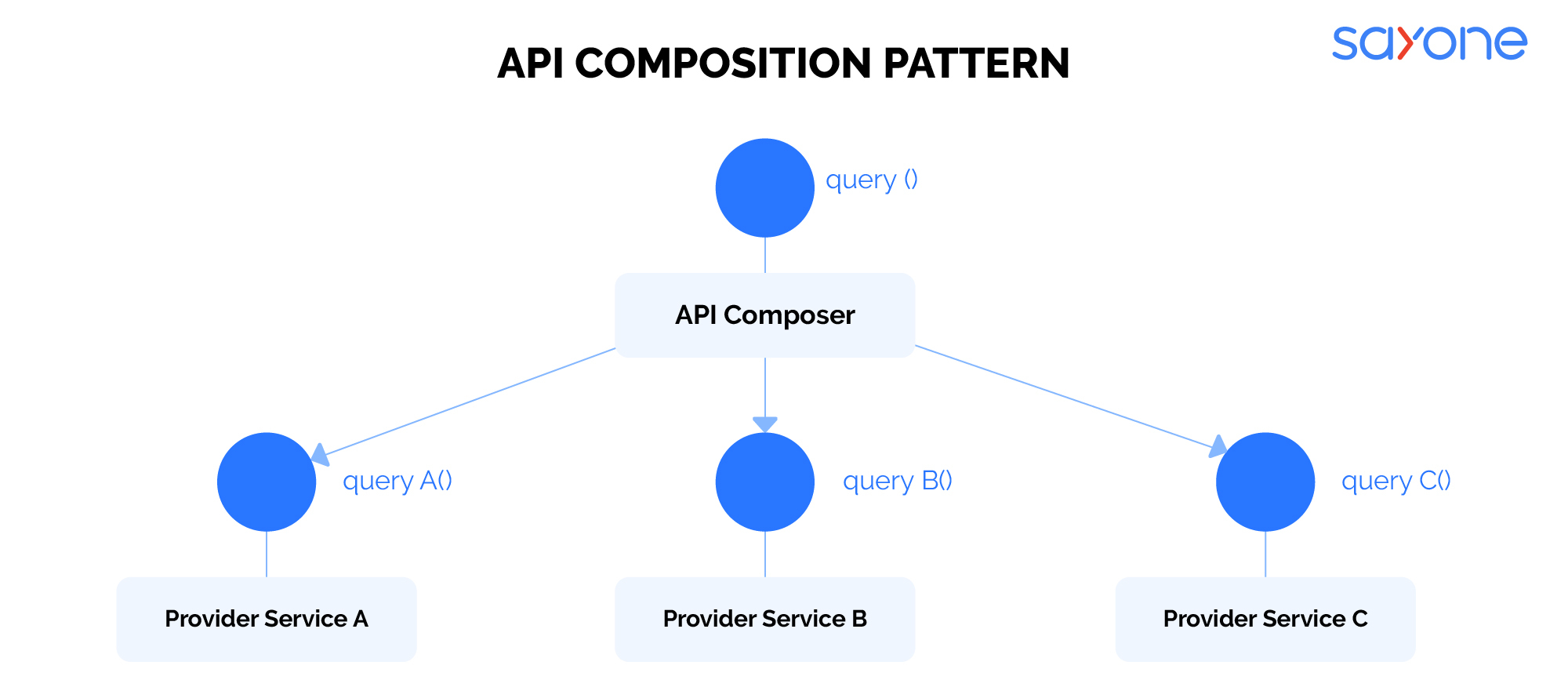
3: API Composition Pattern
This pattern works by way of join in-memory operation. It disturbs the other services for performing the tasks. A query is implemented by invoking specific services that have the required data and combining the results. The API composer then extracts data from different services. However, this pattern may not be the right choice for some queries. This is because its in-memory joins are inefficient when dealing with big datasets.
4: CQRS Pattern
The command query responsibility segregation or CQRS pattern implements queries by way of view databases. In addition, it enables the separation of concerns, meaning it differentiates commands and queries. While query-side modules handle queries, keeping their data synchronized with that of the command-side, the command-side modules manage the operations.
CQRS can be used within a service to define queries. It queries a database and keeps it updated by subscribing to events that are published by the services that own data. The benefit of using this pattern is that it maintains a log of the events in databases along with the messaging queue as and when the user updates data.
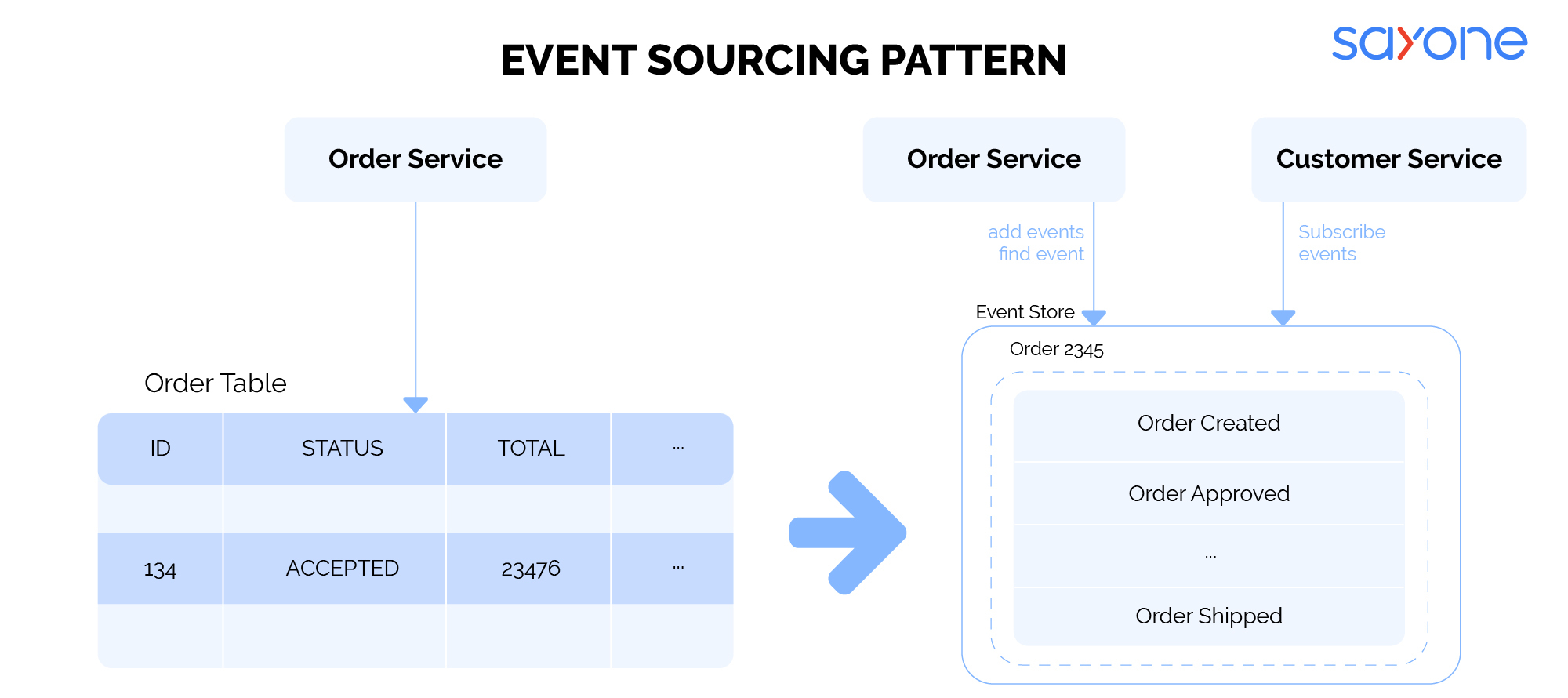
5: Event Sourcing Pattern
According to experts, the event sourcing pattern is the best database for microservices as it offers the right solution. Event sourcing refers to the changing state of activity when an event is generated or added to the event list. In addition to replaying the events that have already been performed within an application, it stores and keeps an events list and uses it to complete actions. This pattern makes use of APIs for retrieving and adding events and enabling services to subscribe to events.
Scalable applications make use of the event sourcing pattern for microservices database management. This is because they need multiple operations to be completed within a fraction of seconds and cannot waste time reconstructing events from scratch.
Though it is possible to create a single microservices database that each service can access with the help of local ACID transactions, you need to think twice before implementing the same. This is because you stand the risk of losing the best features of microservices such as services independency and loose coupling. Besides, the time needed to coordinate services will be much more. Further, services can experience run-time problems and even block each other. Furthermore, a database failure can lead to a system shutdown down.
Are you looking for a microservices vendor? Call SayOne or drop us a note!
1. Limited Storage Capacity: Traditional databases can only store a limited amount of data. This is due to their reliance on physical storage devices such as hard drives, which can only store a finite amount of data.
2. Limited Processing Power: Traditional databases are limited in terms of the amount of processing power they are able to provide. This can be a problem when dealing with large amounts of data or complex queries.
3. Scalability: Traditional databases are not easily scalable, meaning that it can be difficult and expensive to expand the size and capabilities of the database.
4. Low Availability: Traditional databases are prone to downtime and outages due to hardware and software failures.
5. Security: Traditional databases are vulnerable to security breaches, which can lead to data loss or corruption.
The market currently offers several database options. However, it is important to choose the right one for your microservices application project. The first step is to pick the approach to create the database model. The two options available are:
Polyglot persistence – Microservices architecture enables the use of a variety of data storage technologies for different services. In simple terms, a development team has the freedom to choose the persistence technology that is best suited to meet the needs of its services.
Download and read our eBook “Porting from Monolith to Microservices – Is the Shift Worth It”
Multi-model databases – The multi-model database approach supports more than a single abstraction, meaning you can have a single multi-model database but the data model for each service will be different.
The multi-model approach offers operational simplicity when there is only one platform. Polyglot persistence, on the other hand, is the best option for microservices if the application is not very complex. However, the good news is that you can combine these approaches within many services.

Having said that, how do you choose the right database technology for your application that uses microservices? You just need to find answers for a couple of questions:
A few of the non-relational databases (NoSQL) that support different types of data models and stored data are listed below. Microservices allow you to combine many of them.
Document database – This database stores and queries data as JSON-like documents. It is an intuitive data model. Further, a document database is scalable since it is a distributed system. Document databases are best suited for storing catalogs and content management.
Key-value database – In a key-value database, data is stored by employing the key-value method. This means that a key-value represents a set of data. This database is suitable for session-oriented applications. This is because of its ability to process large amounts of data fast.
Graph-based database – A graph-based database makes use of graph structures for queries with nodes, properties, and edges to represent as well as store data. The graph relates stored data to a collection of edges and nodes with the edges representing the relationship between the nodes. Graph databases are used for fraud detection and in recommendation engines and social networks.
Column-based database – In this case, data is stored in columns, making it easier to access data than when it is stored in rows. A column-based database is used for creating a data warehouse. A wide column store is best suited for processing Big Data.
It is not a good idea to use a single relational database when developing a microservices application for the first time. However, you will have to use one when working on an existing monolith. This is because you cannot abandon the existing infrastructure when in the process of switching to microservices. You can start building the microservices with the available database and then slowly split it into many small services. Further, it is possible to use a relational database if are you are planning to apply polyglot persistence. This database is the right option for a service designed for managing low volume stable data.
If your goal is to develop a robust application, it is important to implement a solid microservices data management plan. The best place to start is by choosing the right microservices data management pattern. The next step is to leverage different approaches and create data models and stores. The last step is to choose a microservices database that caters to the needs of each service.
Experts at SayOne Technologies can help you move your application to the microservices architecture in the most seamless manner without impacting your current operations. We can also design the application in such a way that it is easy to maintain and scale up as and when needed. The key factors that have helped become the best microservices solutions providers are:
Are you thinking of shifting to microservices to help your business grow? Call SayOne today
Databases are an essential part of microservices architecture. They provide a way to store and access data across multiple microservices and applications. Databases are used to store data that is required to be shared between various microservices, such as user profiles, configuration settings, and messages. Databases can also be used to store data that is used by a single microservice, such as user data, product information, and preferences. Additionally, databases are used to track and manage transactions that involve multiple microservices. This allows for distributed transactions to be tracked and managed to ensure that data is consistent across all microservices.
Yes, microservices can use different databases. Each microservice can have its own database, or multiple microservices can share a single database. The choice of which database technology to use depends on the specific requirements of the application.
Yes, microservices can have their own databases, as long as there is a way for the different services to communicate and access the data they need. This allows for greater scalability and flexibility of the individual services, as well as allowing for easier debugging and maintenance.
Yes, microservices can share a database. In fact, this is a common practice in microservice architectures, as it can improve efficiency and reduce development and maintenance costs. By sharing a database, microservices can easily access and update data that is stored in a single location. However, it's important to note that in order to ensure data security and scalability, microservices should be designed to use separate databases where possible.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality