
Subscribe to our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


Generating table of contents...
Typically, for monolithic applications that have a single database, it is possible to guarantee their ACID properties. You can also guarantee their ability to perform the transaction by maintaining locks on rows. Also, using transaction managers can help to provide ACID properties on the database.
Simply put, transactional boundaries ensure that transactions are atomic, consistent, isolated and durable and that all the operations within a logical unit of a transaction either succeed or fail.
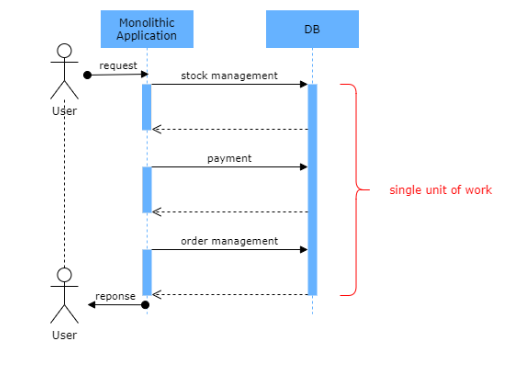
A database transaction is a logical unit independently executed for data retrieval or updates. A logical unit may consist of more than one or multiple tasks.
ACID refers to properties of database transactions that are intended to guarantee validity even if errors or power failures occur. ACID stands for Atomicity, Consistency, Isolation, and Durability. They are defined as:
Atomicity: All operations in a transaction succeed, or every operation can be rolled back.
Consistency: On completion of a transaction, the database is structurally sound.
Download and read our eBook “Porting from Monolith to Microservices – Is the Shift Worth It”.
Isolation: Transactions appear to run sequentially because of moderation by the database so that they do not contend with one another.
Durability: The transaction results are permanent, even if failures occur.
To maintain strong data consistency RDBMS support ACID properties.
Monolithic Database Design – Problems
You can design an application as a single monolithic application when it is simple. If you want to scale the application, you can run more than one instance of the application behind a load balancer if you want to scale up. However, when the application becomes big and the team size increases, this system develops several difficulties.
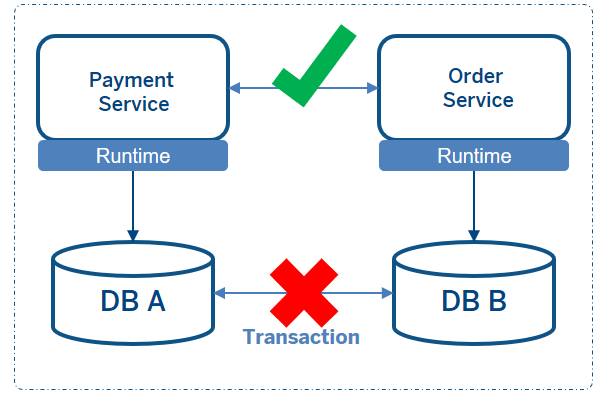
When moving from service-oriented architecture to microservices architecture, the concept of database per service leads to a few challenges because of distributed transactions. Given below are the best ways to deal with distributed transactions.
The two-phase commit protocol is also known as 2PC, a mechanism that helps to implement a transaction across different software components such as multiple databases, message queues, etc.
The important participant in a distributed transaction is the transaction coordinator and in any distributed transaction, there are two steps.
Read our blog “Microservices Database Management – What You Should Know”.
Step 1: Prepare phase
In this phase, all the participants of the transaction prepare for the ‘commit’ and notify the coordinator that they are now ready to complete the transaction.
Step 2: Commit or Rollback phase
In this phase, a ‘commit’ or a ‘rollback’ command is issued by the transaction coordinator to all the participants.
2PC has a problem that it is quite slow when compared to the time that a single microservice takes to operate. Coordinating the transaction amongst different microservices, even when on the same network, can slow down the system. Therefore, this approach is typically not used when the load is heavy.
Are you looking for a microservices vendor? Call SayOne or drop us a note!
The XA standard is a specification that helps to conduct 2PC distributed transactions across supporting resources. A JTA-compliant application server, such as JBoss, GlassFish etc., can support it out of the box.
As an example, the resources that participate in a distributed transaction could be two databases of two different microservices. To use this mechanism to your advantage, the resources have to be deployed on a single JTA platform. This may not always be possible for a microservice architecture system.
Data consistency is strong
Supports ACID features
Complex process and very difficult to maintain
A blocking process leads to high latency and low throughput
Deadlocks can occur between transactions
Transaction coordinator may become a single point of failure
This is a model used to achieve high availability in distributed systems. In an eventually consistent system, inconsistencies may take place till the problem of distributed data is solved. This model cannot be applied to distributed ACID transactions across microservices. The BASE database model is used for eventual consistency. Whereas the ACID model provides a consistent system, the BASE model provides high availability.
BASE acronym (Basically Available, Soft-state, Eventual consistency)
SAGA is a common pattern that helps to operate the eventual consistency model.
Based on a series of services, the SAGA pattern is an asynchronous model. In the SAGA pattern, the distributed transaction is performed by local transactions that are asynchronous on all related microservices. Each service updates its data in a local transaction. SAGA is designed to manage the execution of the sequence of different services.
There is no central coordinator in this case. Each service, after completion of its task, produces an event and each service listens to these events to take an action. This pattern requires a mature event-driven architecture.
Event sourcing stores the state of event changes by using an Event Store. The event store is a message broker that acts as an event database. This SAGA pattern works well when there are only a few steps in a transaction (say, 2 to 4 steps).
A coordinator service (Saga Execution Orchestrator or SEG) sequences transactions according to the business logic. The orchestrator decides which operation should be performed. When an operation fails, the orchestrator undoes the previous steps.
The solution chosen depends on the use case and consistency requirements.
It is better to avoid using distributed transactions across microservices if possible. For this, you can identify transaction boundaries by identifying operations in the same unit of work. Also, it is vital to identify operations that can tolerate possible latencies for consistency.
Though microservices architecture offers advantages such as high availability, automation, and scalability, many changes from traditional methods have to be to obtain maximum efficiency of this architectural style.
At SayOne, we offer independent and stable services that have separate development aspects as well as maintenance advantages. We build microservices especially suited for individuals' businesses in different industry verticals. In the longer term, this would allow your organization/business to enjoy a sizeable increase in both growth and efficiency. We create microservices as APIs with security and the application built in. We provide SDKs that allow for the automatic creation of microservices.
Are you thinking of shifting to microservices to help your business grow? Call SayOne today!
Our comprehensive services in microservices development for start-ups, SMBs, and enterprises start with extensive microservices feasibility analysis to provide our clients with the best services. We use powerful frameworks for our custom-built microservices for different organizations. Our APIs are designed to enable fast iteration, easy deployment, and significantly less time to market. In short, our microservices are dexterous and resilient and deliver the security and reliability required for the different functions.
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.


We collaborate with visionary leaders on projects that focus on quality